Was zwei Jahre Deep-Learning-Experimente über KI in der Praxis lehren

Rückblick aus 2026: Dieser Beitrag fasst meine Hands-on-Experimente von 2018 und 2019 zusammen, dokumentiert in Talks bei PyCon und PyData. Ich lasse ihn bewusst unverändert. Was Sie hier lesen, ist die ehrliche Erfahrung eines Praktikers vor der LLM-Welle: was funktionierte, was scheiterte, und warum die 90-Prozent-Falle keine Theorie ist. Sieben Jahre und mehrere Modell-Generationen später haben sich die Werkzeuge fundamental verändert. Die Lehren über Datenqualität, die Kluft zwischen Forschung und Produktion und das ehrliche Sprechen über Misserfolge sind nicht obsoleter geworden, eher teurer zu ignorieren.
Auf einen Blick
- Die 90%-Falle ist real: Schnelle Prototypen sind einfach. Produktionsreife Systeme kosten erfahrungsgemäß 90% der Zeit.
- Datenqualität schlägt Algorithmen: Ein perfektes Modell auf schlechten Daten ist wertlos.
- Hype und Realität sind verschiedene Welten: Online-Erfolgsbeispiele zeigen geschönte Ausschnitte. Gegenlicht-Fotos scheitern, deutsche Sprachsynthese klingt robotisch.
- Neuronale Netze sind hochspezialisierte Savants: Sehr gut in engen Aufgaben, aber nicht intelligent im menschlichen Sinne.
- Probieren geht über Studieren: Die scheinbar einfache Wette (Kinder-Detektivroman generieren) scheiterte. Die scheinbar utopische Wette (Vorlesestimme auf Consumer-Hardware) funktionierte. Hype und Realität sind selten deckungsgleich.
- Die richtigen Fragen stellen: Garry Kasparov sagte nicht "KI ersetzt uns", sondern "KI ist ein großartiges Werkzeug zum Lernen." Pablo Picasso: "Computer sind nutzlos – sie können nur Antworten geben."
Hands-on statt Hype: Was ich 2018–2019 selbst getestet habe
Zwischen 2018 und 2019 habe ich zwei Jahre intensiver Deep-Learning-Experimente hinter mich gebracht: von Style Transfer über Text-Generierung bis zu Speech Synthesis. Der Grund war nie Marketing oder Buzzwords – sondern die konkrete Frage: "Was funktioniert wirklich, und was nicht?"
Diese Erfahrung ist der Grund, warum ich heute mit C-Level-Teams arbeite. Ich kenne nicht nur die Theorie, sondern die alltägliche Lücke zwischen Beispiel-Code und Produktivbetrieb.
Die 90%-Falle: Der erste Sieg täuscht
Der erste Erfolg war beeindruckend. Ein französischer Comic-Stil aus den 80er Jahren ließ sich beim ersten Versuch erfolgreich auf moderne Comics übertragen. "Oh mein Gott", dachte ich, "Deep Learning kann alles lösen!"
Diese Erkenntnis wiederholt sich in fast jedem KI-Projekt: Die erste Demo begeistert. Dann folgt die Realität. Aus 90% Genauigkeit auf Test-Daten werden 60% in der Produktion. Die letzten 10% kosten erfahrungsgemäß 90% der Zeit.
Das ist kein Deep-Learning-Problem. Das ist Ihr Unternehmensproblem.
Das Datenproblem: Modelle sind nur so gut wie ihre Trainingsdaten
Beim Style Transfer stieß ich auf ein klassisches Muster: Gegenlicht-Fotos wurden zum Desaster. Der Grund war einfach – das COCO-Dataset, auf dem das Modell trainiert wurde, enthielt vermutlich kaum Gegenlicht-Aufnahmen. Das Netz hatte gelernt, was es gesehen hatte, und konnte nicht extrapolieren.
Das ist kein theoretisches Problem. Jedes Unternehmen mit Daten-Bias hat dasselbe Problem: Ein Modell wird nur so gut wie die Perspektive der Daten, auf denen es trainiert wurde. Ein amerikanisches Dataset führt zu amerikanischen Annahmen. Ein Sales-Team-Dataset führt zu Sales-Team-Annahmen.
In Compliance-, Fairness- und Risiko-Diskussionen ist das die zentrale Frage, und sie ist fast nie technisch zu lösen, sondern organisatorisch. Welche Disziplin daraus für Unternehmen folgt (von Data Lineage bis Governance), beschreibt der Beitrag Data Quality Assurance: Fundament für zuverlässige KI-Systeme.
Der überambitionierte Versuch – und seine Grenzen
Ich versuchte, im Stil von 200 "Drei ???"-Hörspielen neue Episoden zu generieren. Das Projekt scheiterte schnell. Die Text-Generierung produzierte zwar deutsche Phantasiewörter wie "Schloko-ljana" (ein erfundenes Wort, halb Schokolade, halb Eigenname), aber keine Geschichten. Chatbots waren Rauschen. Das ist kein anekdotischer Fehler – es war die Realität von RNNs bei Sequenzen, die Sinn erfordern müssen.
Als ich diese Ergebnisse später auf internationalen Konferenzen präsentierte, war die Lacher-Quote im Publikum hoch – und die Nachfragen am Stand drehten sich nicht um die Technik, sondern um genau diesen Punkt: Wann ist eine Demo Spielzeug und wann ein Produkt? Genau diese Frage höre ich heute in Vorstandsterminen wieder, nur ohne Lacher.
Speech Synthesis: Das realistische Potenzial
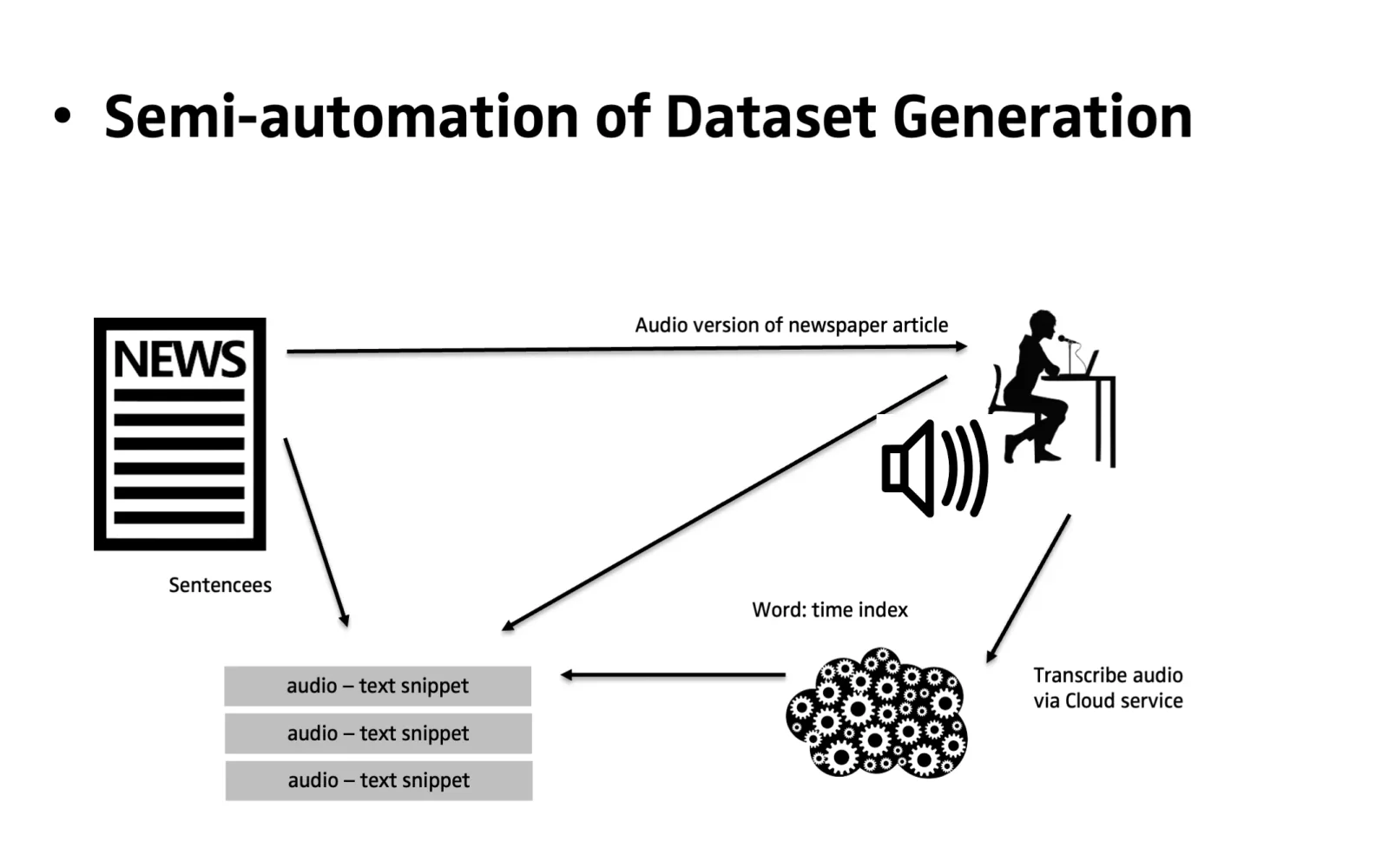
Speech Synthesis war anders. Mit 24 Stunden englischer Audio-Aufnahmen und einer GTX 1080 produzierte ich nach neun Tagen Training Stimmen, die "Once upon a time there was a little mermaid" sprechen konnten. Nicht Alexa-fertig, aber für die Ressourcen beeindruckend.
Deutsche Sprachsynthese? Das offenbarte ein anderes Problem: Es gab keine brauchbaren deutschen Datasets. Ich baute selbst einen. Das Ergebnis war verständlich, aber robotisch – und gelegentlich gab es Aussprachefehler, die in einem Kinderhörspiel unangemessen gewesen wären. Das ist keine Inkompetenz. Das ist Datenqualität.
Was Sie daraus mitnehmen sollten: Ein Großteil der Forschung erreicht niemals den Produktivbetrieb. Aus meiner Praxis sind es etwa 95% – und nicht, weil Forscher faul sind, sondern weil der Weg von "funktioniert im Labor" zu "läuft 24/7 unter Last" ein eigener Beruf ist.
Probieren geht über Studieren
Die übergreifende Lehre aus diesen Experimenten ist banal und doch entscheidend: Probieren geht über Studieren. Einen Kinder-Detektivroman generieren zu lassen wäre (entlang des damaligen Hypes) die einfache Wette gewesen. Auf Consumer-Equipment eine deutsche Vorlesestimme zu trainieren, erschien utopisch. Die Realität zeigte genau das Gegenteil. Wer die Diskrepanz zwischen Marketing-Folie und Maschinenraum verstehen will, muss selbst Hand anlegen: Kein Whitepaper, keine Vendor-Demo und auch kein Blogpost ersetzen das.
Forschung vs. Produktion: Eine unüberwindliche Kluft?
Was ich nach diesen zwei Jahren wusste: Forschungscode ist nicht Produktionscode. Ich sah Implementierungen von Facebook in Python 2.7. Jupyter-Notebooks voll mit Closures, in denen niemand außer dem Autor wusste, welche Bibliothek wofür zuständig war. Nach 38 Stunden Debugging fragte ich mich genau das.
Das ist keine Kritik an Forschern. Sie bauen Prototypen, und das ist auch ihr Job. Aber es erklärt, warum so viele Forschungsergebnisse niemals in den Produktivbetrieb wandern – und warum der vermeintlich "letzte Schritt" zur Produktivierung der eigentliche Berg ist.
Scheitern als Teil der Strategie
Daraus folgt nicht, dass Unternehmen nun reflexhaft zwei Dutzend KI-Prototypen aufsetzen sollten. Worauf es ankommt, ist die Steuerung: Welche Ergebnisse erwarten wir, woran messen wir sie, und wie schaffen wir Sicherheit für alle Beteiligten. In diesem Rahmen ist Scheitern ausdrücklich erlaubt – vorausgesetzt, es wird sichtbar gemacht, dokumentiert und ausgewertet.
Was ich in der Praxis zu oft sehe: KI-Leuchtturmprojekte werden zum Erfolg getrieben, weil nur Erfolg belohnt wird. Wer als Sponsor, Projektleiterin oder Team auf einer Bühne stehen will, kann sich Misserfolge nicht leisten – also werden sie umgedeutet, geschönt oder weggelassen. Das Ergebnis sind Folien voller Erfolgsmetriken und eine Organisation, die aus dem eigentlichen Projekt nichts lernt.
Eine produktive Kultur belohnt das Gegenteil: diejenigen, die offen über Fehler, Sackgassen und nötige Re-Justierungen sprechen. Diese Berichte sind das, woraus andere Teams lernen – und genau dort entsteht der eigentliche Mehrwert. Erfahrungsgemäß sind es die Teams, die Scheitern als Teil ihrer Methodik begreifen, die am Ende die belastbaren Ergebnisse liefern. Nicht die blinkenden Demos auf den Quartalsfolien.
In regulierten Branchen ist diese Kulturfrage doppelt relevant: Compliance und Risikomanagement leben davon, dass Risiken früh benannt werden. Eine Organisation, die ihre KI-Misserfolge intern verschweigt, baut genau die Schwäche auf, die sie in jedem Audit-Bericht verhindern soll.
Was ich Ihnen damit zeigen möchte
Diese Experimente waren nicht dazu gedacht, ein Startup zu starten. Sie waren dazu gedacht, die Realität zu verstehen. Genau das brauchen Unternehmen jetzt: nicht die Marketing-Version von KI, sondern die Produktionsversion.
Wenn Ihr Unternehmen KI strategisch einführen möchte – von der Vorstandsstrategie über die technische Umsetzung bis zur Code-Qualität – dann sprechen wir die gleiche Sprache. Ich weiß nicht nur, was funktioniert. Ich weiß auch, wo es bricht.
Welcher Teil Ihrer KI-Roadmap trägt heute Substanz, und welcher noch Hype?
Lassen Sie uns sprechenLinks zum Thema
- ▶ Alexander Hendorf - Deep Learning with PyTorch for Fun and Profit2018-08
- ▶ PyCon.DE 2018: Deep Learning With PyTorch For More Fun And Profit (Part II) - Alexander CS Hendorf2018-11
- ▶ Alexander Hendorf - Deep Learning with PyTorch for Fun and Profit2019-06
- ▶ Alexander C.S. Hendorf: Speech Synthesis with Tacotron2 and PyTorch | PyData Amsterdam 20192019-06
Erkenntnisse aus zwei Jahren eigener Deep-Learning-Experimente, präsentiert auf PyCon und PyData 2018 und 2019. Die Modelle dieser Zeit wirken aus 2026er Perspektive klein. Die Disziplin, mit der man sie produktionsreif machte (oder eben nicht), hat sich nicht verändert.
Material zu den Talks