What Two Years of Deep-Learning Experiments Teach About AI in Practice

A look back from 2026: This piece consolidates my hands-on experiments from 2018 and 2019, documented in talks at PyCon and PyData. I am leaving it deliberately unchanged. What you read here is the honest experience of a practitioner before the LLM wave: what worked, what failed, and why the 90-percent trap is not theory. Seven years and several model generations later, the tooling has changed fundamentally. The lessons about data quality, about the gap between research and production, and about speaking honestly about failure have not become more obsolete, only more expensive to ignore.
At a Glance
- The 90% trap is real: quick prototypes are easy. Production-ready systems eat 90% of the time, in my experience.
- Data quality beats algorithms: a perfect model on bad data is worthless.
- Hype and reality live in different worlds: online success stories are carefully picked excerpts. Backlit photos fail, German speech synthesis sounds robotic.
- Neural networks are highly specialised savants: excellent at narrow tasks, but not intelligent in any human sense.
- Hands-on beats theory: the apparently easy bet (generating a children's detective novel) failed. The apparently utopian bet (a narrator voice on consumer hardware) worked. Hype and reality rarely line up.
- Ask the right questions: Garry Kasparov did not say "AI replaces us"; he said "AI is a great tool for learning." Pablo Picasso: "Computers are useless, they can only give us answers."
Hands-on Instead of Hype: What I Tested Myself in 2018–2019
Between 2018 and 2019 I spent two years on intensive deep-learning experiments: from style transfer through text generation to speech synthesis. The motivation was never marketing or buzzwords. It was the concrete question: "what actually works, and what doesn't?"
That experience is why I work with C-level teams today. I don't just know the theory; I know the everyday gap between sample code and production.
The 90% trap: don't trust the first win
The first success was striking. A 1980s French comic style transferred cleanly onto modern comics, on the very first try. "Oh my god," I thought, "deep learning can solve anything!"
That moment repeats itself in almost every AI project: the first demo dazzles. Then reality arrives. 90% accuracy on test data becomes 60% in production. The last 10% eat 90% of the time.
That is not a deep-learning problem. That is your organisation's problem.
The data problem: models are only as good as their training data
With style transfer I ran into a classic pattern: backlit photos were a disaster. The reason was simple: the COCO dataset the model had been trained on contained almost no backlit shots. The network had learned what it had been shown and could not extrapolate.
That is not a theoretical problem. Every company with biased data hits the same wall: a model is only as good as the perspective of the data it was trained on. An American dataset produces American assumptions. A sales-team dataset produces sales-team assumptions.
In compliance, fairness and risk discussions, this is the central question, and it is almost never solvable technically; it is an organisational one. Which discipline this implies for companies (from data lineage to governance) is laid out in the post Data Quality Assurance: The Foundation for Reliable AI Systems.
The over-ambitious attempt, and its limits
I tried to generate new episodes in the style of 200 "Drei ???" audio dramas, a German children's detective series. The project fell apart quickly. Text generation produced German nonsense words like "Schloko-ljana" (an invented word, half chocolate, half proper name), but no actual stories. The chatbots were noise. That is not an anecdotal failure. It was the reality of RNNs on sequences that have to carry meaning.
When I later presented these results at international conferences, the laughs from the audience came easily, and the questions at the booth afterwards were not about the technology. They were about exactly this point: when is a demo a toy, and when is it a product? It is the same question I now hear in board meetings, only without the laughs.
Speech synthesis: the realistic potential
Speech synthesis was different. With 24 hours of English audio recordings and a single GTX 1080, after nine days of training I had voices that could speak "once upon a time there was a little mermaid." Not Alexa-ready, but impressive given the resources.
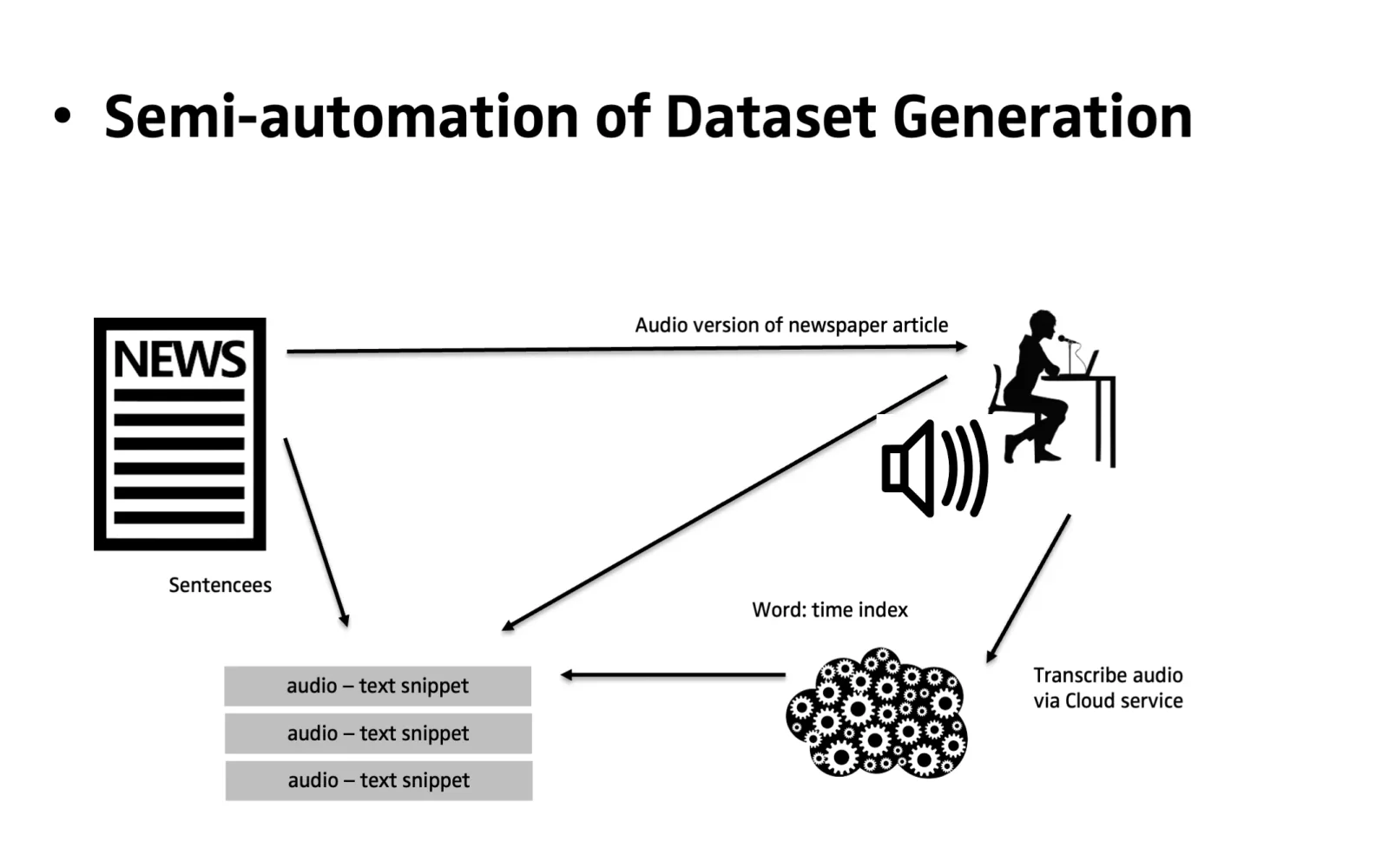
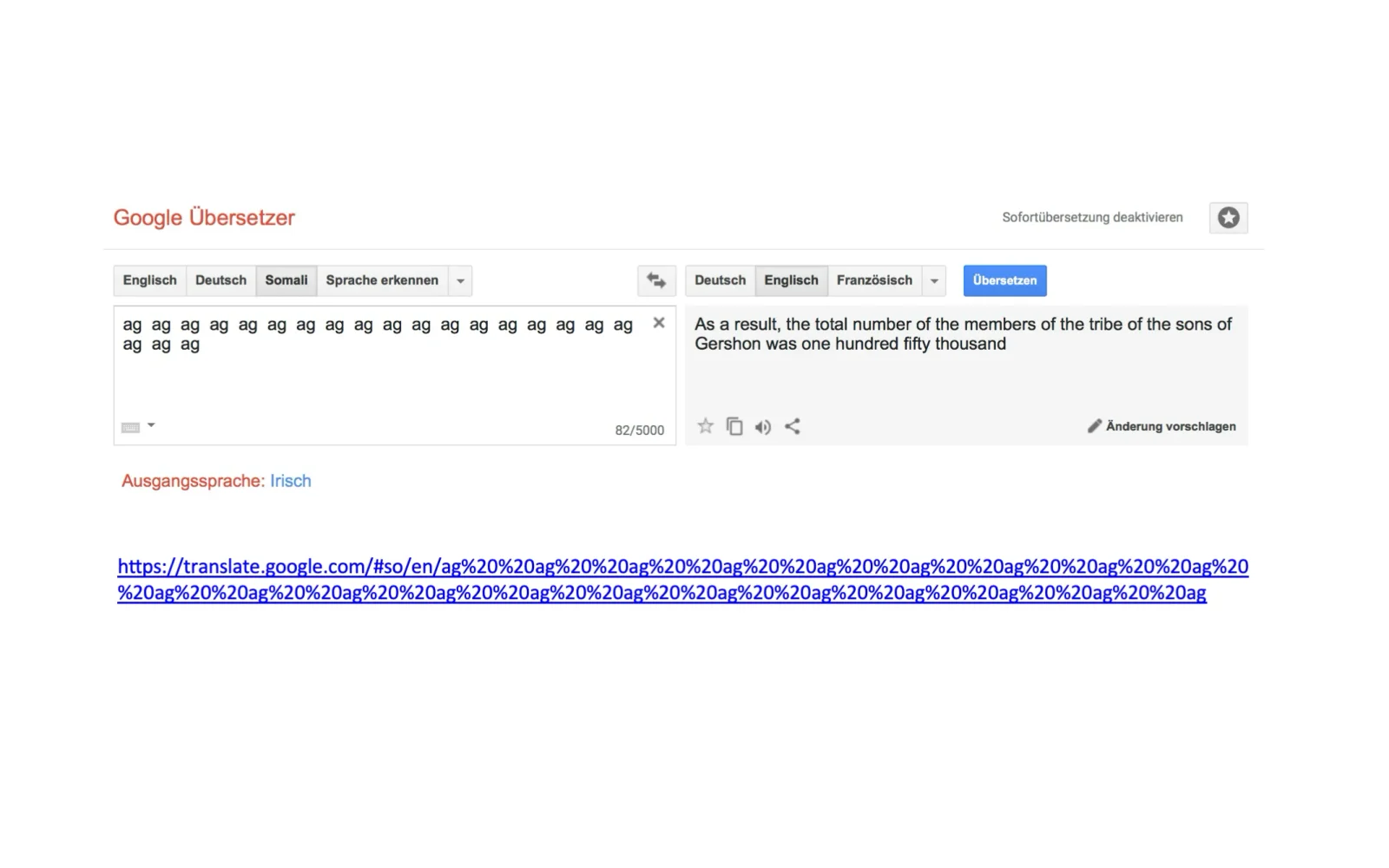
German speech synthesis? That revealed a different problem: there were no usable German datasets. So I built one myself. The result was understandable but robotic, and occasionally produced pronunciation slips that would have been inappropriate in a children's audio book. That is not incompetence. That is data quality.
What you should take away from this: most research never reaches production. From my own practice, the share is somewhere around 95%, not because researchers are lazy, but because the path from "works in the lab" to "runs 24/7 under load" is a discipline of its own.
Hands-on beats theory
The overarching lesson from these experiments is mundane but decisive: hands-on beats theory. Generating a children's detective novel (riding the hype of the day) would have been the easy bet. Training a German narrator voice on consumer-grade hardware looked utopian. Reality showed exactly the opposite. If you want to understand the gap between marketing slide and engine room, you have to put your own hands on it. No white paper, no vendor demo and no blog post will replace that.
Research vs. Production: An Insurmountable Gap?
What I knew after those two years: research code is not production code. I saw implementations from Facebook still in Python 2.7. Jupyter notebooks stuffed with closures, where nobody but the author knew which library was responsible for what. After 38 hours of debugging I asked exactly that question.
That is not a criticism of researchers. They build prototypes; that is the job. But it explains why so much research never makes it into production, and why the supposed "last step" to productionising is in fact the climb itself.
Failure as Part of the Strategy
None of this means your organisation should now reflexively spin up two dozen AI prototypes. What matters is how you steer the work: which results do we expect, how do we measure them, and how do we create safety for everyone involved? Within that frame, failure is explicitly allowed, provided it is made visible, documented and reviewed.
What I see far too often in practice: flagship AI projects get pushed to "success" because only success is rewarded. A sponsor, a project lead or a team that wants to be on stage cannot afford visible setbacks, so setbacks get reframed, polished, or quietly dropped. The result is slides full of success metrics and an organisation that learns nothing from the actual project.
A productive culture rewards the opposite: the people who speak openly about mistakes, dead ends and necessary course corrections. Those reports are what other teams learn from, and that is where the real value is created. In my experience, the teams that treat failure as part of their methodology are the ones that deliver durable results in the end. Not the flashy demos on the quarterly slides.
In regulated industries this cultural question matters twice over: compliance and risk management depend on risks being named early. An organisation that quietly hides its AI failures internally is building exactly the weakness it is supposed to prevent in every audit report.
What I Want to Show You
These experiments were not designed to launch a start-up. They were designed to understand reality. And that is exactly what companies need now: not the marketing version of AI, but the production version.
If your organisation wants to introduce AI strategically (from board strategy through technical execution down to code quality) then we speak the same language. I don't just know what works. I also know where it breaks.
Which part of your AI roadmap carries substance today, and which still carries hype?
Let's talkRelated links
- ▶ Alexander Hendorf - Deep Learning with PyTorch for Fun and Profit2018-08
- ▶ PyCon.DE 2018: Deep Learning With PyTorch For More Fun And Profit (Part II) - Alexander CS Hendorf2018-11
- ▶ Alexander Hendorf - Deep Learning with PyTorch for Fun and Profit2019-06
- ▶ Alexander C.S. Hendorf: Speech Synthesis with Tacotron2 and PyTorch | PyData Amsterdam 20192019-06
Insights from two years of my own deep-learning experiments, presented at PyCon and PyData 2018 and 2019. The models of that period look small from a 2026 perspective. The discipline required to get them production-ready (or to recognise that they wouldn't make it) has not changed.
Material from the Talks