Data Quality Assurance: Fundament für zuverlässige KI-Systeme
Das ist der zentrale Punkt: Datenqualität ist nichts, was man nebenbei erledigt oder mit einem Tool einfach „fixt“. Sie ist eine strategische Entscheidung mit Auswirkungen auf Ihre gesamte KI-Transformationsstrategie.

Welcome to the Wild West! – So könnte man die aktuelle Situation beim Thema Datenqualität beschreiben. Überall wird immer noch von "Data is the new Oil" gepredigt, doch ich habe in jahrelanger Arbeit mit Unternehmen eine unbequeme Wahrheit erkannt: Nicht jede Menge Rohöl lässt sich raffinieren.
Viele Organisationen sammeln wild Daten, ohne jemals eine funktionsfähige Raffinerie aufzubauen. Sie haben Volumina, aber keine Verlässlichkeit. Und dann wundern sie sich, warum ihre KI-Systeme scheitern – nicht an den Algorithmen, sondern an den Daten darunter.
Dieser Artikel zeigt, warum Data Quality Assurance nicht optional ist, sondern das Fundament jedes erfolgreichen KI-Systems darstellt. Es geht um eine strategische Sichtweise: Wie baue ich Datenqualität von vornherein ein, nicht als Reparaturarbeit am Ende?
Kontext: Dieser Beitrag fasst meinen Vortrag im Rahmen von Science Sparks Start-Ups an der Universität Heidelberg zusammen, einem Transfer-Format, in dem wissenschaftsnahe Ausgründungen Erfahrungen aus der Enterprise-Beratung gespiegelt bekommen. Der Punkt ist nicht akademisch: Was große Organisationen über Jahre teuer gelernt haben, können junge Spin-offs vermeiden, bevor es zur strukturellen Hypothek wird. Die Beobachtungen stammen aus Beratungsmandaten in etablierten Unternehmen: Der Adressat sind Gründerinnen und Gründer, die ihre Datenarchitektur jetzt richtig aufsetzen können, statt sie später teuer zu reparieren.
Die unbequeme Wahrheit über Daten in der Realität
Studierende lernen mit perfekten, bereinigten Datensätzen wie Iris oder Titanic. In echten Unternehmen sieht es anders aus: Ein Chaos aus unvollständigen, inkonsistenten und veralteten Daten, das über Jahrzehnte gewachsen ist.
Das sind nicht Einzelfälle – das ist Normalität. In fast jedem Unternehmen, das ich beraten habe, existierte mindestens ein sogenanntes "Gespenster-Feld": ein Datensatz, dessen Bedeutung niemand mehr kannte, der aber in kritischen Prozessen noch verwendet wurde. In einem Fall war es ein Feld, das vor zehn Jahren für einen bestimmten Geschäftsprozess gedacht war – dieser Prozess existierte längst nicht mehr, aber die Daten wurden weiterhin erfasst.
Die häufigsten Probleme, mit denen ich konfrontiert werde: Unvollständige Werte, die dazu führen, dass KI-Modelle Lücken erfinden müssen. Inkonsistente Formate, bei denen Adresse mal in einem, mal in drei Feldern gespeichert wird. Veraltete Daten, die nicht aktualisiert werden, weil niemand Verantwortung trägt. Fehlende Standardisierung, die jede Abteilung mit eigenen Konventionen pflegt. Datensilos, bei denen die Kundendaten in fünf verschiedenen Systemen existieren. Und dahinter: schlechte Data Governance – keine klaren Verantwortlichkeiten, keine Prozesse, keine Dokumentation.
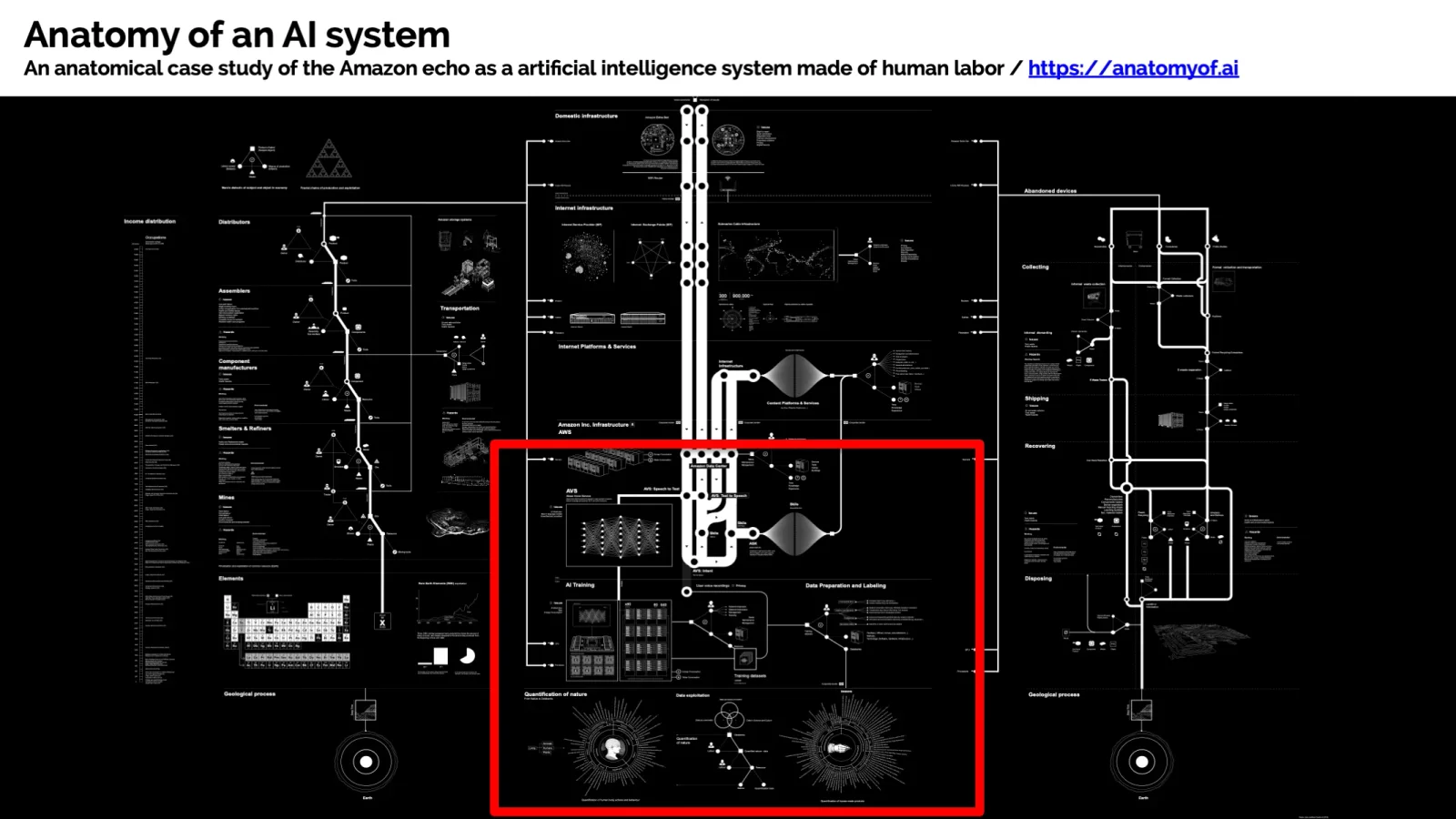
Die Anatomie eines KI-Systems
Jedes funktionsfähige KI-System – ob Amazon Echo oder ein Recommendation Engine in einer Bank – ruht auf einem unsichtbaren Fundament: Technologie ist nur die Spitze des Eisbergs. Darunter liegt ein riesiger Berg aus Datenquellen, menschlicher Arbeit und komplexen Abhängigkeiten.
In Enterprise-Umgebungen wird dieses Problem exponentiell schwieriger. Daten kommen nicht aus einer Quelle, sondern aus Menschen (manuelle Eingaben, User Feedback), Maschinen (Sensoren, APIs, Logfiles) und Legacy-Systemen, die über Jahrzehnte gewachsen sind. Jedes System hat seine eigene Struktur, eigene Datentypen, eigene Fehlerquellen.
Das klassische Silo-Problem: Daten sind dezentral verteilt, jedes System hat seine Gatekeeper, Integration ist fehleranfällig, und da nie jemand verantwortlich für das Ganze war, entwickelt sich eine uneinheitliche Data Governance. Das Ergebnis ist eine Organisation, die zwar Datenmengen hat, aber nicht weiß, wie sie zusammenhängen.
Data Quality: Definition und Dimensionen
Datenqualität ist nicht abstrakt – sie ist die Eignung von Daten für den beabsichtigten Verwendungszweck. Das bedeutet konkret: Eine Kundenliste mit 50.000 Einträgen ist nutzlos, wenn 30 % davon unvollständige Adressen haben oder Duplikate sind.
Die wesentlichen Dimensionen sind:
Genauigkeit
ist die Frage, die ich zuerst stelle: Entsprechen die Daten der Realität? Nicht "sieht es richtig aus", sondern kann ich es verifizieren? Ich habe Systeme gesehen, in denen Namen absichtlich gefälscht wurden (Kundenschutz), aber dann Analysen darauf aufbauten und zu völlig falschen Schlüssen führten.
Glaubwürdigkeit
bedeutet: Können die beteiligten Menschen den Daten vertrauen? Das klingt weich, ist aber geschäftskritisch. Wenn ein Vertriebsmitarbeiter nicht glaubt, dass die Kundendaten im CRM korrekt sind, verlässt er sich auf sein eigenes Netzwerk – und Sie verlieren Datenintegration.
Vollständigkeit
ist in KI-Systemen besonders kritisch. Fehlende Werte führen nicht nur zu ungenauen Prognosen; sie führen dazu, dass Modelle systematisch Lücken halluzinieren. Eine Bank, die bei 20 % der Kunden das Einkommen nicht erfasst hat, trainiert ein Kreditrisikomodell, das implizit "fehlende Information = niedriges Risiko" lernt.
Konsistenz
über Systemgrenzen hinweg ist in großen Organisationen oft das größte Problem. Ein Kunde kann in fünf verschiedenen CRM-Systemen mit fünf verschiedenen Adressen existieren. Eine Transaktion wird mal mit Uhrzeit, mal nur mit Datum erfasst.
Aktualität
ist nuanciert. Nicht alle Daten müssen in Echtzeit aktuell sein; manche können 30 Tage alt sein. Aber Sie müssen wissen, wie alt Ihre Daten sind und ob sie für Ihren Use Case akzeptabel sind.
Gültigkeit und Eindeutigkeit
runden das Bild ab: Entsprechen die Daten definierten Regeln? Gibt es unbeabsichtigte Duplikate?
KI-spezifische Datenqualitätsprobleme
Bei KI-Systemen wird schlechte Datenqualität zur existenziellen Gefahr. Das ist nicht wie eine fehlerhafte Excel-Tabelle; das ist wie ein Flugzeug mit undichtem Treibstofftank.
Bias in Trainingsdaten
ist das klassische Problem: Ein Kreditvergabemodell, das auf historischen Daten trainiert ist, in denen bestimmte Gruppen systematisch benachteiligt wurden, wird diese Benachteiligungen perpetuieren – und womöglich verstärken. Das ist nicht nur ethisch problematisch; es ist regulatorisch hochriskant. Ich bin mit Unternehmen konfrontiert worden, die ihre Modelle vom Markt nehmen mussten, weil Bias erst nach der Produktivnahme erkannt wurde. Wie solche Verzerrungen konkret aussehen (bis hin zu Style-Transfer-Modellen, die Gegenlicht-Fotos systematisch verfehlen, weil das Trainings-Dataset sie kaum enthielt), habe ich aus eigenen Hands-on-Experimenten in Was zwei Jahre Deep-Learning-Experimente über KI in der Praxis lehren dokumentiert.
Fehlende Repräsentation
ist subtiler: Wenn Sie ein Modell für Creditscoring mit Daten trainieren, die zu 95 % weiße, männliche Kunden repräsentieren, werden marginale Gruppen von Anfang an benachteiligt. Das Modell funktioniert statistisch großartig – auf der Mehrheitspopulation.
Data Drift
ist die Realität in Production: Die Welt verändert sich. Kundennachfrage verschiebt sich, Wirtschaftsbedingungen ändern sich, Ihre Konkurrenz reagiert. Das Modell, das 2023 perfekt funktionierte, liefert 2025 falsche Vorhersagen – nicht weil etwas kaputt ist, sondern weil die Datenverteilung sich verschoben hat.
Scalability-Probleme
zeigen sich, wenn Sie von 100 Transaktionen täglich auf 100.000 skalieren. Was als Test funktioniert, bricht in Production zusammen – nicht immer wegen des Codes, sondern weil Datenqualitätsprobleme bei großen Volumina exponentiell sichtbar werden.
Das typische Anti-Pattern: Technologie vor Fundament
Die glitzernde KI im Frontend, die marode Dateninfrastruktur im Backend
In meiner Beratung sehe ich immer wieder das gleiche Muster: Die glitzernde KI im Frontend, die marode Dateninfrastruktur im Backend. Vorstände wollen das Thema "KI" checken – und beauftragen schnell ein Machine Learning Projekt. Niemand fragt: Sind unsere Daten überhaupt geeignet?
Das Resultat: Große Investitionen in Tools, Infrastruktur und Talent, aber das System funktioniert nicht. Weil die Daten es nicht zulassen.
Dann kommt die nächste typische Reaktion: "Wir brauchen bessere Tools!" Also kauft man noch eine Data Quality Plattform für viel Geld. Aber ohne Governance, ohne verantwortliche Personen, ohne dokumentierte Standards. Das Tool sitzt ungenutzt herum, während Datenqualität weiterhin ein punktuelles Problem bleibt, das beim nächsten Notfall repariert wird.
Technologie-Wildwuchs: Das MAD-Landscape-Problem
Tools sind nur Tools - keine Heilsbringer.
Das MAD (ML, AI & Data) Landscape 2024 ist in einem Wort: überwältigend. Hunderte von Tools für Data Quality, Governance und Monitoring. Ständig neue, Venture Capital-finanzierte Start-ups, die das "Problem" der Datenqualität lösen wollen. Jeder behauptet, die Lösung zu sein.
Das ist exakt das, was ich auf der Startseite "Technologie-Wildwuchs" nenne. Und es ist die große Falle für Unternehmen: Nicht die Technik ist das Problem – es ist die fehlende Strategie, welche Technik überhaupt nötig ist.
Ich habe mit Organisationen gearbeitet, die fünf verschiedene Data Quality Tools gleichzeitig einsetzten – weil jeder Layer (Data Engineering, Analytics, ML) sein "richtiges" Tool hatte. Keins davon war falsch. Zusammen waren sie ein Alptraum.
Hinzu kommt: Die Nachfrage nach echten Data Quality Experten ist riesig. Aber wenige haben echte Erfahrung in Production-Systemen bei größeren Skalen. Noch weniger verstehen die Kombination aus Technik und organisatorischer Datenkultur. Data Quality bleibt in vielen Organisationen eine einsame Mission: Ein oder zwei Menschen kämpfen gegen Windmühlen, während der Rest der Organisation davon ausgeht, dass "Qualität passiert automatisch".
Strategische Lösungsansätze: Vom Startup bis zur Enterprise
Der Weg zu zuverlässiger Datenqualität unterscheidet sich je nach Organisationsgröße, aber die Prinzipien sind gleich.
Mindset
Quality by Design, nicht Reparatur. Das ist der Kernunterschied zwischen Organisationen, bei denen Datenqualität funktioniert, und solchen, wo sie ständig kaputt geht. Quality by Design bedeutet: Datenqualität ist nicht etwas, das "danach" kommt. Sie ist Teil des Systems von Tag 1. Wenn ein neuer Kundendatensatz erfasst wird, sind die Validierungen bereits da. Wenn eine neue Datenquelle integriert wird, ist Data Lineage dokumentiert.
Monitoring und Observability
Monitoring und Observability sind dann das Frühwarnsystem. Ein Data Catalog gibt Überblick über vorhandene Daten und ihre Herkunft. Automated Quality Checks laufen kontinuierlich im Hintergrund. Alerting benachrichtigt Sie, wenn Probleme entstehen – nicht, wenn Sie bereits Geschäftswirkung haben.
Governance muss proportional sein
Start-ups brauchen nicht die gleiche Governance wie ein Finanzinstitut. Aber es muss klare Verantwortlichkeiten geben: Wer trägt Verantwortung für welche Daten? Welche Standards gelten? Die Dokumentation – was bedeuten die Daten, wie entstehen sie – ist oft vernachlässigt und ist später tausendmal teuer.
Daten
Technisch bedeutet das: Datenstrukturen müssen sich entwickeln können (Schema Evolution). Eingehende Daten müssen validiert werden. Der Ursprung jedes Datenpunkts muss nachverfolgbar sein (Data Lineage). Das klingt komplex, lässt sich aber mit modernen Plattformen relativ überschaubar umsetzen.
Konkrete Schritte: Je nach Reifegrad
Für Start-ups ist der Vorteil klar: Ihr könnt von Anfang an richtig machen. Definiert Datenqualitätskriterien für euren Use Case. Implementiert Validationen von Anfang an. Dokumentiert Datenquellen und ihre Bedeutung. Das sind kleine Anstrengungen am Anfang, die euch Jahre ersparen.
Für etablierte Unternehmen ist es aufwendiger, aber nicht unmöglich. Ein Data Quality Assessment zeigt euch objektiv, wo ihr steht. Das ist nicht angenehm – ich habe solche Assessments durchgeführt, die etwa 40-60 % der Daten als "problematisch" eingestuft haben. Aber ohne Diagnose gibt es keine Heilung. Dann braucht es Stakeholder Alignment: Der CFO, der CIO, der Leiter Analytics müssen verstehen, warum das wichtig ist. Das ist politischer als technisch. Dann kommt schrittweise Verbesserung – nicht alles auf einmal, sondern systematisch die höchsten Risiken zuerst. Und schlussendlich: Tool-Konsolidierung. Weniger Tools, dafür richtig eingesetzt und tatsächlich genutzt.
Für alle gilt: Datenqualität ist nicht optional. Es ist genauso fundamental wie Sicherheit oder Compliance – nur dass die meisten Unternehmen das noch nicht verstanden haben. Prevention ist billiger als Cure. Und das wichtigste: People über Technology. Die beste Data Quality Plattform hilft nichts, wenn niemand die Daten tatsächlich pflegt, dokumentiert und für ihre Qualität verantwortlich ist.
Ausblick: Die Rolle von Automatisierung
KI wird Datenqualität in Zukunft stärker automatisieren – Anomalienerkennung, Outlier-Detection, sogar automatische Datenbereinigung werden smarter. Aber die strategischen Fragen bleiben menschlich:
Welche Daten sind kritisch? Das kann nur das Unternehmen beantworten. Wie schlecht ist es akzeptabel? Ein Data Quality Level von 95 % ist in einer Ticketing-Anwendung akzeptabel; beim Kreditscoring nicht. Welche Kosten rechtfertigen welche Verbesserungen? Das ist eine Business-Entscheidung, keine technische.
Und das Wichtigste bleibt: Kultur. Wenn in einer Organisation nicht verankert ist, dass Datenqualität bedeutsam ist, wird auch die beste Technologie nicht funktionieren.
Fazit: Fundament statt Aktionismus
Das ist der zentrale Punkt: Data Quality ist nicht etwas, das man nebenbei macht oder mit einem Tool "fixed". Es ist eine strategische Entscheidung, die Auswirkungen auf Ihre gesamte KI-Transformationsstrategie hat.
Mein Beratungsansatz, den ich aus jahrelanger Erfahrung entwickelt habe, besteht darin: Fundament statt Aktionismus. Das bedeutet, dass wir nicht mit "schnell ein KI-Modell trainieren" anfangen, sondern mit der unbequemen Frage: "Sind unsere Daten überhaupt geeignet?" Wenn nein – und in den meisten Fällen ist das so – müssen wir das zuerst beheben.
Das klingt teuer und zeitaufwendig. Kurzzeitig ist es das. Langfristig sparen Sie massiv Kosten, weil Sie nicht ständig Systeme reparieren müssen, deren Grundlagen marode sind.
Wie tragfähig ist die Datenbasis unter Ihren KI-Systemen?
Lassen Sie uns sprechenDieser Artikel basiert auf meinem Vortrag bei Science Sparks Start-Ups an der Universität Heidelberg (einem Transfer-Format für wissenschaftsnahe Ausgründungen) und auf meiner langjährigen Beratung von Organisationen in ihrer KI-Transformation. Die hier beschriebenen Muster stammen aus Enterprise-Mandaten; das Briefing für Gründerinnen und Gründer ist: diese Fehler nicht wiederholen, sondern von Anfang an strukturell vermeiden.
Ausgewählte Slides