Data Quality Assurance: The Foundation for Reliable AI Systems
Data quality is not a tooling problem. It is a strategic decision, one that determines how far your AI transformation can actually go.

Welcome to the Wild West! That is a fair description of the current state of play around data quality. Everywhere people still preach "Data is the new oil", and yet years of work with companies have taught me one uncomfortable truth: not every barrel of crude can be refined.
Many organisations collect data wildly without ever building a working refinery. They have volume, but no reliability. And then they wonder why their AI systems fail, not on the algorithms, but on the data underneath.
This article makes the case that Data Quality Assurance is not optional but the foundation of every successful AI system. The point is strategic: how do I build data quality in from the start, rather than as repair work at the end?
Context: This piece summarises my talk at Science Sparks Start-Ups at Heidelberg University, a transfer format that mirrors enterprise consulting experience back to research-driven spin-outs. The point is not academic: what large organisations have learned the hard way over years, young spin-outs can avoid before it becomes a structural mortgage. The observations come from advisory mandates inside established companies: the audience is founders who can set up their data architecture properly now, instead of expensively repairing it later.
The Inconvenient Truth About Data in the Real World
Students learn with perfectly clean datasets like Iris or Titanic. Inside real companies it looks different: a chaos of incomplete, inconsistent and outdated data that has grown over decades.
These are not isolated cases. This is the norm. In almost every company I have advised, at least one so-called "ghost field" existed: a data field whose meaning no one remembered, but which was still being used in critical processes. In one case it was a field that had been intended ten years ago for a specific business process. That process had long since disappeared, but the data was still being captured.
The problems I most often run into: incomplete values, which force AI models to invent the gaps. Inconsistent formats, where an address sits in one field one time and three the next. Outdated data that no one updates because no one is responsible. Missing standardisation, with each department maintaining its own conventions. Data silos, where customer data lives in five different systems. And underneath all of it: poor data governance, no clear responsibilities, no processes, no documentation.
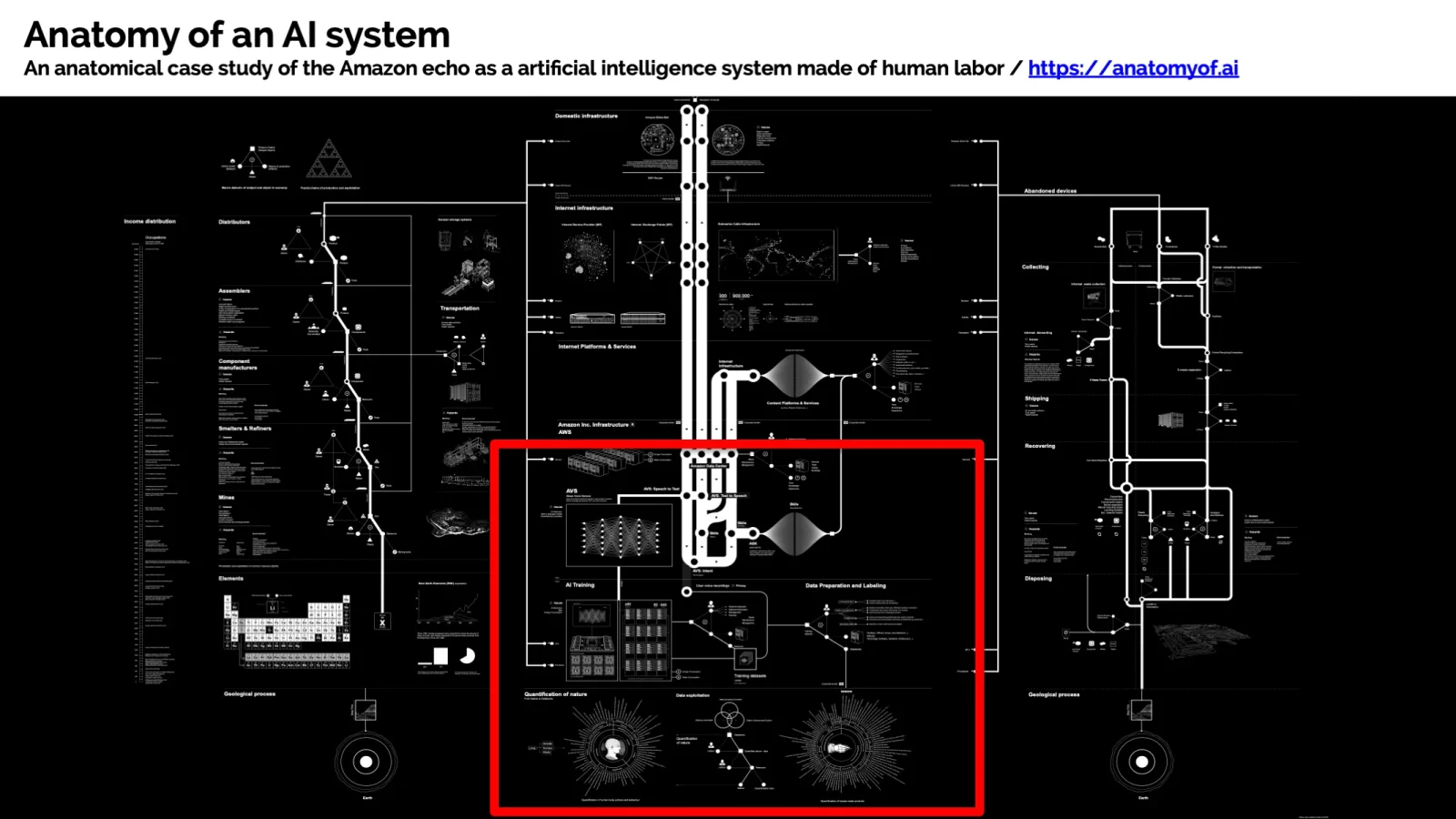
The Anatomy of an AI System
Every working AI system (whether Amazon Echo or a recommendation engine inside a bank) rests on an invisible foundation: technology is just the tip of the iceberg. Underneath sits a vast mountain of data sources, human work and complex dependencies.
In enterprise environments this problem becomes exponentially harder. Data does not come from one source but from people (manual entries, user feedback), machines (sensors, APIs, log files) and legacy systems that have grown over decades. Each system has its own structure, its own data types, its own sources of error.
The classic silo problem: data is distributed decentrally, every system has its gatekeepers, integration is error-prone, and because no one was ever responsible for the whole, an inconsistent data governance regime emerges. The result is an organisation that has volumes of data but no idea how the pieces connect.
Data Quality: Definition and Dimensions
Data quality is not abstract. It is the fitness of data for its intended use. Concretely: a customer list with 50,000 entries is useless if 30 percent have incomplete addresses or are duplicates.
The essential dimensions:
Accuracy
The first question I ask: do the data correspond to reality? Not "does it look right", can I verify it? I have seen systems in which names were deliberately falsified (for customer protection), and then analyses were built on top of them and led to entirely wrong conclusions.
Believability
Can the people involved trust the data? That sounds soft, but it is business-critical. If a sales rep does not believe the customer data in the CRM is correct, they fall back on their own network, and you lose the integration.
Completeness
In AI systems this is particularly critical. Missing values do not just lead to imprecise forecasts; they cause models to systematically hallucinate around the gaps. A bank that has not captured income for 20 percent of its customers trains a credit-risk model that implicitly learns "missing information equals low risk".
Consistency
Across system boundaries, this is often the biggest problem in large organisations. A single customer can exist in five different CRM systems with five different addresses. A transaction is captured with a timestamp one day, with only the date the next.
Timeliness
Nuanced. Not all data has to be real-time fresh; some can be 30 days old. But you have to know how old your data is, and whether that is acceptable for your use case.
Validity and Uniqueness
Round out the picture: do the data conform to defined rules? Are there unintended duplicates?
AI-Specific Data Quality Problems
In AI systems, poor data quality becomes an existential hazard. This is not like a faulty Excel sheet; it is like an aircraft with a leaking fuel tank.
Bias in training data
The classic problem: a credit-decision model trained on historical data in which certain groups were systematically disadvantaged will perpetuate those biases, and possibly amplify them. This is not just ethically problematic; it is regulatorily high-risk. I have seen companies forced to pull their models from the market because bias was only detected after they went live.
Missing representation
More subtle: if you train a credit-scoring model on data that is 95 percent white male customers, marginal groups are disadvantaged from the outset. The model performs statistically beautifully, on the majority population.
Data drift
The reality in production: the world changes. Customer demand shifts, economic conditions change, your competition reacts. The model that worked perfectly in 2023 delivers wrong predictions in 2025, not because something broke, but because the data distribution has shifted.
Scalability problems
Surface when you scale from 100 transactions a day to 100,000. What works in test breaks in production, not always because of the code, but because data quality issues become exponentially visible at volume.
The Typical Anti-Pattern: Technology Before Foundation
The shiny AI in the front end, the crumbling data infrastructure in the back end
In my advisory work I keep seeing the same pattern: shiny AI in the front end, crumbling data infrastructure in the back end. Boards want to tick the "AI" box, and quickly commission a machine-learning project. No one asks: are our data even fit for this?
The result: large investments in tools, infrastructure and talent, but the system does not work. Because the data does not allow it.
Then the next typical reaction: "We need better tools!" So another data-quality platform gets bought, expensively. But without governance, without responsible owners, without documented standards. The tool sits unused while data quality continues to be a spot problem, repaired in the next emergency.
Tooling Sprawl: The MAD Landscape Problem
Tools are just tools, not saviours.
The MAD (ML, AI & Data) Landscape 2024 is, in a word, overwhelming. Hundreds of tools for data quality, governance and monitoring. A constant stream of new VC-funded start-ups, each promising to "solve" data quality. Everyone claims to be the answer.
This is exactly what I call "technology sprawl" on the home page. And it is the big trap for companies: the technology is not the problem; the missing strategy about which technology is even needed is.
I have worked with organisations that ran five different data-quality tools at once, because each layer (data engineering, analytics, ML) had its "right" tool. None of them was wrong. Together they were a nightmare.
On top of that: demand for genuine data-quality experts is huge. But few have real experience in production systems at meaningful scale. Even fewer understand the combination of technology and organisational data culture. In many organisations, data quality remains a lonely mission: one or two people fight windmills while the rest of the organisation assumes "quality just happens".
Strategic Approaches: From Start-Up to Enterprise
The path to reliable data quality differs by organisational size, but the principles are the same.
Mindset
Quality by design, not repair. This is the core difference between organisations where data quality works and ones where it keeps breaking. Quality by design means: data quality is not something that comes "later". It is part of the system from day one. When a new customer record is created, the validations are already there. When a new data source is integrated, data lineage is documented.
Monitoring and observability
Are then the early-warning system. A data catalogue gives an overview of what data exists and where it comes from. Automated quality checks run continuously in the background. Alerting notifies you when problems emerge, not when they have already had business impact.
Governance has to be proportional
Start-ups do not need the same governance as a financial institution. But there must be clear responsibilities: who owns which data? Which standards apply? Documentation (what do the data mean, how do they come about) is often neglected and is a thousand times more expensive later.
Data
Technically that means: data structures must be able to evolve (schema evolution). Incoming data must be validated. The origin of every data point must be traceable (data lineage). That sounds complex but is relatively manageable on modern platforms.
Concrete Steps: By Level of Maturity
For start-ups, the advantage is clear: you can do it right from the start. Define data-quality criteria for your use case. Implement validations from day one. Document data sources and their meaning. Small efforts at the start that save you years.
For established companies it is harder, but not impossible. A data-quality assessment shows you objectively where you stand. That is not pleasant. I have run assessments that classified 40-60 percent of the data as "problematic". But without diagnosis there is no cure. Then you need stakeholder alignment: the CFO, the CIO, the head of analytics all have to understand why this matters. That is more political than technical. Then comes incremental improvement, not everything at once, but systematically tackling the highest risks first. And finally: tool consolidation. Fewer tools, used properly and actually adopted.
For everyone: data quality is not optional. It is as fundamental as security or compliance, except that most companies have not understood that yet. Prevention is cheaper than cure. And the most important point: people over technology. The best data-quality platform is useless if no one actually maintains, documents and takes responsibility for the quality of the data.
Outlook: The Role of Automation
AI will increasingly automate data quality: anomaly detection, outlier detection, even automatic data cleansing will get smarter. But the strategic questions remain human:
Which data is critical? Only the company can answer that. How bad is acceptable? A data-quality level of 95 percent is acceptable in a ticketing application; in credit scoring it is not. Which costs justify which improvements? That is a business decision, not a technical one.
And the most important thing remains: culture. If it is not embedded in an organisation that data quality matters, even the best technology will not work.
Conclusion: Foundations, Not Firefighting
This is the central point: data quality is not something you do on the side or "fix" with a tool. It is a strategic decision that affects your entire AI transformation strategy.
The advisory approach I have developed over years comes down to this: foundations, not firefighting. That means we do not start with "let's quickly train an AI model"; we start with the uncomfortable question: "are our data even fit for this?" If not (and in most cases they are not), we have to fix that first.
That sounds expensive and time-consuming. In the short term it is. In the long term you save massively, because you do not constantly have to repair systems whose foundations are crumbling.
How load-bearing is the data foundation under your AI systems?
Let's talkThis article is based on my talk at Science Sparks Start-Ups at Heidelberg University (a transfer format for research-driven spin-outs) and on years of advising organisations through their AI transformation. The patterns described here come from enterprise mandates; the briefing for founders is: don't repeat these mistakes, avoid them structurally from the start.
Selected Slides