Agentic AI & Automation: Drei Monate Coding-Agenten in Operations
Coding-Agenten schaffen Wert, wenn Aufgaben klar dokumentiert, eng begrenzt und überprüfbar sind. Sie schaffen Risiko, wenn sie ohne explizite Governance in Prozesse mit Urteilskraft, Datenqualität oder mehrstufigen Abhängigkeiten eingebunden werden.
Die zentrale Frage ist deshalb nicht, ob Agenten produktiv genutzt werden, sondern unter welchem Governance-Rahmen. Welche Anwendungsfälle geeignet sind und wie Ergebnisse überprüft werden, ist keine technische Detailfrage, sondern eine strategische Entscheidung.

Auf einen Blick
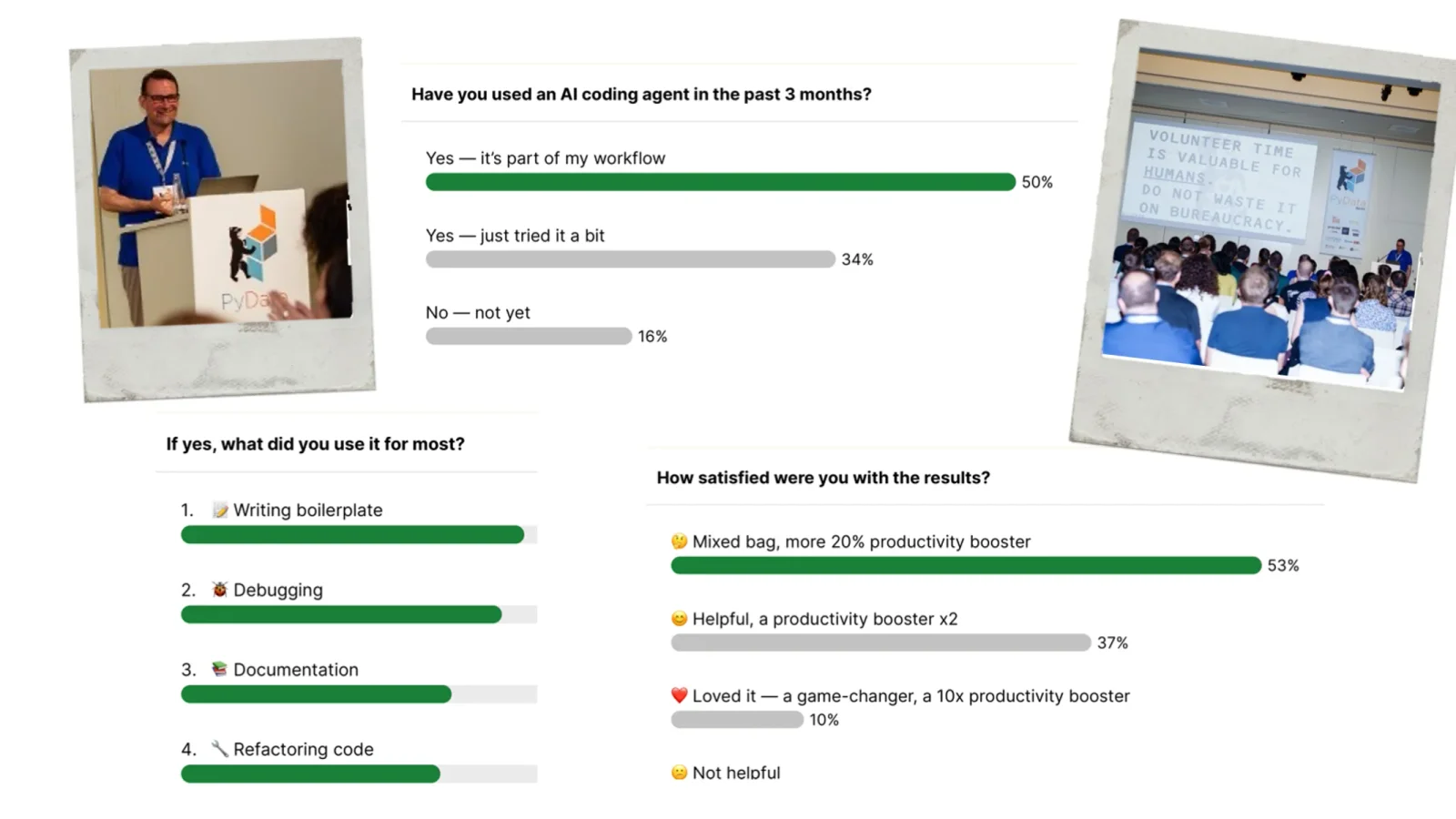
- Setting: 1.500 Teilnehmer, drei Monate intensives Arbeiten mit Coding-Agenten in der Operations-Vorbereitung der PyCon DE & PyData. Kein kontrolliertes Experiment, sondern eine anekdotische Bestandsaufnahme über mehrere Modelle hinweg: Claude Code, Gemini, Qwen Coder Plus, Codex.
- Kernbefund: Agenten arbeiten zuverlässig in eng definierten, gut dokumentierten Aufgaben, und sie brechen ausgerechnet dort, wo man es am wenigsten erwartet: bei Datennormalisierung, mehrstufigen Pipelines, gut dokumentierten Security-Patterns.
- Strategische Einordnung: Forschung schätzt den Anteil generativer KI an der Wertschöpfung in analytischen Programmen auf unter 15 Prozent. Die übrigen 85 Prozent bleiben klassische Arbeit: Analytik, Machine Learning, Datenqualität, Vorhersage, Governance.
- Risikomuster: Augmented Arrogance: Agenten liefern selbstbewussten, formal korrekten Output, ohne nachzufragen. Das eigentliche Risiko ist nicht die sichtbare Halluzination, sondern die unbemerkte im produktiven Prozess.
- Praxis: das Short Leash Principle: eng umrissene Anwendungsfälle, häufige Commits, explizite Eskalation, und ein bewusster Verzicht auf Werkzeug-Vielfalt. Erfahrene Ingenieure bleiben unverzichtbar, als Überprüfer, nicht weil sie weniger schreiben.
Eine Konferenz als Versuchsanordnung
Die PyCon DE & PyData ist eine durchgehend ehrenamtlich organisierte Konferenz mit 1.500 Teilnehmern. In den drei Monaten vor und während der Konferenz haben wir bewusst experimentiert: Welche Aufgaben in der Konferenz-Operations lassen sich an KI-Coding-Agenten delegieren, und wo trägt das Versprechen, wo bricht es?
Diese Konstellation ist ein dankbares Experimentierfeld. Eine Community-Konferenz wird durch ehrenamtliches Engagement getragen: Domänen-Expertinnen und -Experten aus unterschiedlichen Feldern, die für eine begrenzte Zeit zusammenwirken, voneinander lernen und gemeinsam gestalten, ohne unter Konzern-Vorgaben zu stehen. Audit-Druck, Change-Advisory-Boards und lange Freigabewege fallen weg; der Weg zwischen Beobachtung und Korrektur ist kurz. Genau dort liegt auch der eigentliche Wert dieser Konferenz: im Engagement der Beteiligten. Automatisierung setzt deshalb mit doppeltem Effekt an: Sie nimmt Ehrenamtlichen mechanische Arbeit ab und verschiebt deren Zeit dorthin, wo Programmqualität und Besuchererfahrung tatsächlich entstehen.
Das ist kein kontrolliertes Experiment, sondern eine anekdotische Auswertung über mehrere Modelle hinweg: Claude Code, Gemini, Qwen Coder Plus, Codex. Was bleibt, ist eine subjektive, aber operative Bestandsaufnahme aus echtem Betrieb. Sie ist, mit der nötigen Anpassung an Audit- und Freigaberahmen, übertragbar auf jede Organisation, die heute über Agenten in produktiven Prozessen nachdenkt.
Der Versuchskatalog
Die Aufgaben, die wir an Agenten delegiert haben, lasen sich unspektakulär: Sprecher- und Organisator-Tickets ausstellen und nachhalten, einschließlich Stornos und Nachrückern. Sponsor- und Marketing-Reports aggregieren. LinkedIn-Beiträge zur Konferenz sammeln (über 250 Posts pro Konferenz, redaktionell auswertbar). 120 Beitragstitel-Posts mit Bild, Beschreibung und Link zum Video automatisch erzeugen. Video-Rohschnitte am Folgetag bereitstellen, über Pausenfolien-Erkennung mit Computer Vision. 1.500 Teilnehmer mit den passenden Rollen in Discord eingliedern. Daneben einzelne Visualisierungen, Audiobuch-Pipelines, kleine Tools für die internen Abläufe.
Nichts davon ist glamourös. Aber jede dieser Aufgaben kostet ehrenamtliche Zeit, wenn ein Mensch sie tut, und jede dieser Aufgaben taucht in äquivalenter Form in jedem Konzern wieder auf, nur in anderem Maßstab und unter anderem Compliance-Druck.
Wo die Agenten tragen, und wo sie unerwartet brechen
Nach drei Monaten Arbeit ist das Muster eindeutig, und es hängt weniger am Werkzeug als an der Aufgabenform.
Wo Agenten zuverlässig liefern
Gut dokumentierte APIs (das Ticketing-System Pretix mit sauberer REST-Schnittstelle als Paradebeispiel: Der Agent hat hier wirklich gut funktioniert). Browser-Automatisierung mit definierter Interaktion (LinkedIn-Datenerhebung, überraschend gut, denn LinkedIn ist eigentlich schwer auslesbar). Computer-Vision-Aufgaben mit klarer Kante (Pausenfolien-Erkennung für das automatische Video-Cutting). Boilerplate-Code. Einzelne Visualisierungen, ohne dass der Agent tiefe Bibliothekskenntnis mitbringen muss.
Wo sie unerwartet brechen
Ausgerechnet dort, wo man es am wenigsten erwartet hat. Datennormalisierung: Die Frage, ob „Acme Corp" und „ACME Corporation" derselbe Eintrag sind, sollte trivial sein, ist es aber nicht. CI/CD-Pipelines für Security-Scans auf Azure, gut dokumentierter Korpus, sollte trivial sein, ist es aber nicht. Mehrstufige Pipelines mit unterschiedlichen Aufgaben, etwa ein vierstufiger Video-Release-Prozess (Video holen, Metadaten ziehen, auf YouTube veröffentlichen, Folge-Schritte auslösen), sollte trivial sein, ist es aber nicht. Konsistente Datenpipelines mit sauberer Fehlerbehandlung in allgemeiner Form, auch hier blieb der Agent unter Niveau.
Eine Szene aus den drei Monaten zeigt das Muster, das hinter diesen Befunden liegt. Der Agent hatte eine Karte gebaut, die visualisierte, woher die Konferenzteilnehmer kommen. Optisch beeindruckend, technisch sauber. Erst beim Blick in die Rohdaten wurde sichtbar, dass nur etwa ein Drittel der Teilnehmerdaten überhaupt im Datensatz war: Die Affiliation-Felder waren uneinheitlich befüllt, der Agent hatte das nicht thematisiert. Aus einer scheinbaren Aussage über die Herkunft der Community wäre eine Visualisierung geworden, die nicht trägt. Die Lehre aus solchen Momenten ist nicht „Agenten sind unbrauchbar". Sie ist: Ohne den Menschen, der mit Erfahrung gegenliest, ist jeder Agent in produktiver Verantwortung ein Risiko.
Daraus folgt eine zweite Beobachtung, die in der Praxis Geld kostet: Datenqualität bleibt das tragende Fundament. Eine schicke Visualisierung mit fragwürdiger Datengrundlage entsteht heute schneller als je zuvor, und sie ist gefährlicher als ein offen schlechtes Dashboard, weil sie überzeugt.
Augmented Arrogance
Die Stochastic-Parrots-Debatte (Bender, Gebru und andere, 2021) hat den Kern beschrieben, und Yann LeCun hat das Bild aufgenommen: Große Sprachmodelle sind, so eindrucksvoll sie in agentischer Verpackung wirken, leistungsfähige Mustergeneratoren ohne Verständnis. In der Praxis sehe ich daraus eine spezifische Pathologie entstehen, die ich in den beiden zugrunde liegenden Vorträgen Beyond Agents und How We Automate Chaos als Augmented Arrogance bezeichnet habe.
Das Muster: Agenten liefern stets eine Antwort, und diese Antwort sieht überzeugend aus. Sie fragen nicht nach. Sie sagen nicht „ich stecke fest, hilf mir". Sie produzieren Code, der formal sauber, semantisch aber falsch ist. Sie entscheiden ungefragt, dass eine Visualisierung mit drei zusätzlichen Elementen „besser" wäre. Sie fügen Schritte ein, die niemand verlangt hat. Auch explizite Anweisungen im Prompt („Es ist in Ordnung, nach Hilfe zu fragen, wenn du nicht weiterkommst") ändern wenig daran. Das Verhalten ist tief in Modell und Systemprompt verankert.
Das ist das Gegenteil menschlicher Unsicherheit. Eine erfahrene Junior-Ingenieurin sagt: „Ich bin mir nicht sicher." Ein Agent sagt: „Hier ist die Lösung". Auch wenn sie falsch ist. Im Konzernkontext entsteht daraus ein konkretes Risiko: Eine Projektleitung sieht hochpolierten Output, vertraut dem System, und drei Wochen später bricht ein Prozess, weil ein fundamentaler Fehler unentdeckt durchgelaufen ist.
Genau das ist das Kernrisiko unkontrollierter Agentennutzung in Unternehmen. Es ist nicht der spektakuläre Halluzinationsfall, sondern der unauffällige.
Short Leash Principle
Die direkte Antwort auf dieses Risiko ist eine Praxis, die ich als Short Leash Principle bezeichne. Sie besteht aus vier Komponenten, alle aus dem Betrieb hervorgegangen.
Erstens: enge Definition des Anwendungsfalls
Der Agent löst nicht „das Problem", er löst eine konkrete, klar abgegrenzte Aufgabe. LinkedIn-Daten auslesen: ja. „LinkedIn-Strategie entwickeln": nein. Video-Rohschnitte erzeugen: ja. Die inhaltliche Strategie für die Social-Media-Kanäle überarbeiten: nein. Diese Trennung ist keine Bescheidenheit, sondern Risikomanagement.
Zweitens: häufige Commits, und das Recht auf Reset
Agenten geraten in Schleifen, fügen Code hinzu, ohne zu löschen, oder schweifen vom Auftrag ab. Wer häufig committet (oder den Agenten dazu anhält), kann auf einen sauberen Stand zurücksetzen, statt eine unklare Schichtung von Zusatz-Features zu sortieren. Das ist Versionsverwaltung als Governance.
Drittens: Werkzeug-Diät statt Werkzeug-Schaufenster
Es ist verlockend, jeden verfügbaren MCP-Server, jeden Sub-Agenten, jedes neue Framework anzuschließen. In der Praxis beschleunigt das nichts, sondern zerstreut Aufmerksamkeit und Kontextfenster. Weniger Werkzeuge, gezielter eingesetzt, schlagen die volle Werkzeugkiste.
Viertens: explizite Eskalation und der Mensch als Lesekraft
Der Agent muss eine erkennbare Liste von Fällen haben, in denen er sagen darf: „Das kann ich nicht, hier braucht es einen Menschen." Und der Mensch muss den Code lesen, nicht nur den nächsten Prompt schreiben. Der ehrlichste Befund aus drei Monaten Praxis: Agenten machen aus Schreibern Leser. Wer mehr promptet als liest, baut Schulden auf, die später teuer werden.
Erfahrene Ingenieure und Data Scientists werden in dieser Welt nicht weniger wichtig, sondern wertvoller.
Die strategische Konsequenz daraus: Erfahrene Ingenieure und Data Scientists werden in dieser Welt nicht weniger wichtig, sondern wertvoller. Ihr Schwerpunkt verschiebt sich vom reinen Bauen in die Rolle der Überprüfungs- und Governance-Instanz. Wer diese Rollen abbaut, weil „Agenten bald alles übernehmen", legt eine strukturelle Schwäche in das eigene Programm; sichtbar wird sie erst im Audit oder im Schadenfall, dann jedoch teuer.
Die 15-Prozent-Größenordnung
Diese Erfahrung trifft eine Schätzung, die mir aus der Forschung wiederholt begegnet und die ich aus der Arbeit in vergleichbaren Programmen bestätigt sehe: Generative KI deckt in einem analytischen oder softwareintensiven Programm höchstens etwa 15 Prozent der Wertschöpfung ab. Die übrigen rund 85 Prozent bleiben das, was sie immer waren: Analytik, Machine Learning, Datenqualität, Vorhersagemodellierung, Sicherheit, Governance.
Das klingt wie eine technische Aussage. Es ist aber eine organisatorische. Sie heißt: Wer schwerpunktmäßig in Agenten-Werkzeuge investiert, ohne die klassischen Disziplinen weiter aufzubauen, schafft eine instabile Basis. Die Agenten beschleunigen einen schmalen Ausschnitt. Sie ersetzen nicht das Fundament. Wer auf dieser Annahme die Personalplanung aufbaut und Engineering-Stellen kürzt, macht eine strategische Fehlkalkulation, die sich erst im Schaden zeigt.
Innovation entsteht in dieser Welt nicht in einzelnen Agenten, sondern an den Schnittstellen: zwischen Domänen, Datenquellen, Systemen. Das setzt Menschen voraus, die diese Schnittstellen verstehen und gestalten können. Nicht Menschen, die schnell prompten.
So What
Die operative Lehre aus drei Monaten Arbeit mit verschiedenen Coding-Agenten ist unspektakulär, aber tragend. Agenten erzeugen Wert dort, wo Aufgaben dokumentiert, eng umrissen und überprüfbar sind. Sie erzeugen Risiko dort, wo sie ohne explizite Governance in Prozesse mit Urteilskraft, Datenqualität oder mehrstufigen Abhängigkeiten gestellt werden, und genau dort versagen sie häufig auch dann, wenn die Aufgabe oberflächlich gut dokumentiert wirkt.
Wer das nicht systematisch durchdenkt, baut Risiken in den eigenen Stack ein, die im Audit oder im Schadenfall schwer zu korrigieren sind. Die Frage ist also nicht, ob Agenten in einer Organisation produktiv genutzt werden, sie ist, mit welchem Governance-Rahmen das geschieht. Beides, die Auswahl der geeigneten Anwendungsfälle und die Definition der Überprüfungsstruktur, ist eine strategische, keine technische Entscheidung.
Wie sieht der Governance-Rahmen für Agenten in Ihrem Programm aus?
Lassen Sie uns sprechenAusgewählte Folien


Links zum Thema
Beobachtungen aus der Organisation der PyCon DE & PyData (1.500 Teilnehmer, ehrenamtliches Programm) und aus den Vorträgen Beyond Agents (März 2025) und How We Automate Chaos (September 2025).