Agentic AI & Automation: Three Months of Coding Agents in Operations
The operational lesson from three months of working with different coding agents is unglamorous but decisive: agents create value when tasks are well documented, narrowly scoped, and verifiable. They create risk when introduced without explicit governance into processes that require judgment, data quality, or multi-step dependencies.
The central question is therefore not whether agents can be used productively, but under which governance framework. Identifying suitable use cases and defining the review structure is not a technical detail. It is a strategic decision.

At a Glance
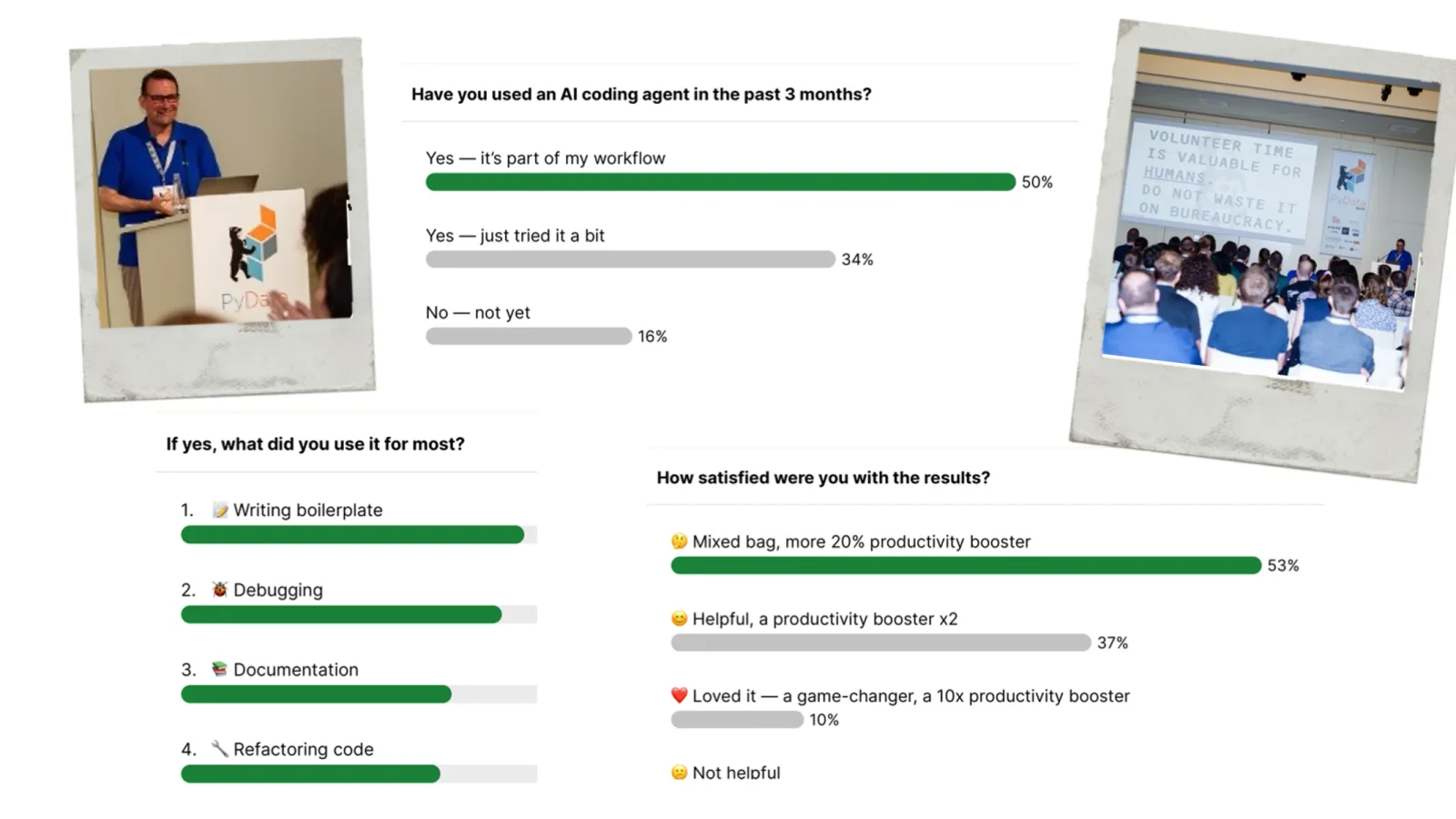
- Setting: 1,500 attendees, three months of intensive work with coding agents in the run-up to PyCon DE & PyData operations. Not a controlled experiment, but an anecdotal stocktaking across several models: Claude Code, Gemini, Qwen Coder Plus, Codex.
- Core finding: Agents perform reliably on tightly defined, well-documented tasks, and break precisely where you'd least expect them to: data normalisation, multi-step pipelines, well-documented security patterns.
- Strategic framing: Research puts generative AI's share of value creation in analytical programmes at less than 15 percent. The remaining 85 percent stay what they always were: analytics, machine learning, data quality, prediction, governance.
- Risk pattern: Augmented Arrogance: agents deliver confident, formally correct output without ever asking back. The real risk is not the visible hallucination, but the unnoticed one inside a productive process.
- Practice: the Short Leash Principle: narrowly scoped use cases, frequent commits, explicit escalation, and a deliberate refusal to chase tool variety. Experienced engineers stay indispensable, as reviewers, not because they write less.
A Conference as a Field Test
PyCon DE & PyData is a fully volunteer-organised conference with 1,500 attendees. In the three months leading up to and during the event we deliberately experimented: which tasks in conference operations can be delegated to AI coding agents: where do the promises hold, where do they break?
This setup is a rewarding test bed. A community conference runs on volunteer engagement: domain experts from different fields who come together for a limited stretch, learn from one another and build together, without sitting under enterprise mandates. Audit pressure, change advisory boards and long approval paths fall away; the loop between observation and correction is short. That is also where the actual value of this conference sits: in the engagement of the people involved. Automation therefore lands with a double effect: it takes mechanical work off volunteers and shifts their time toward where programme quality and the attendee experience are actually created.
This is not a controlled experiment but an anecdotal account across several models: Claude Code, Gemini, Qwen Coder Plus, Codex. What remains is a subjective but operational stocktaking from real-world ops. With the necessary adjustment to audit and approval frames, it transfers to any organisation thinking today about putting agents into productive processes.
The Catalogue of Attempts
The tasks we delegated to agents read accordingly unspectacular: issuing and tracking speaker and organiser tickets, including cancellations and late additions. Aggregating sponsor and marketing reports. Collecting LinkedIn posts about the conference (more than 250 posts per edition, editorially usable). Auto-generating 120 talk-promotion posts with image, description and link to the video. Producing rough video cuts the day after, using break-slide detection via computer vision. Onboarding 1,500 attendees into Discord with the right roles. Alongside that: individual visualisations, audiobook pipelines, small tools for internal flows.
None of this is glamorous. But each of these tasks costs volunteer time when a human does it, and each shows up in equivalent form in any enterprise, only at a different scale and under different compliance pressure.
Where Agents Hold Up, and Where They Break Unexpectedly
After three months of work the pattern is unambiguous, and it depends less on the tool than on the shape of the task.
Where agents reliably deliver
Well-documented APIs (the Pretix ticketing system with its clean REST interface as the standout example: the agent really worked here). Browser automation with defined interaction (LinkedIn data collection, surprisingly good, given that LinkedIn is genuinely hard to scrape). Computer-vision tasks with a clean edge (break-slide detection for automatic video cutting). Boilerplate code. Individual visualisations, without the agent needing deep library knowledge.
Where they break unexpectedly
Precisely where you'd have expected them to succeed. Data normalisation: the question of whether "Acme Corp" and "ACME Corporation" are the same record should be trivial; it isn't. CI/CD pipelines for security scans on Azure, well-documented corpus, should be trivial; it isn't. Multi-step pipelines with heterogeneous tasks, e.g. a four-stage video release process (fetch the video, pull the metadata, publish to YouTube, trigger the follow-up steps), should be trivial; it isn't. Consistent data pipelines with proper error handling in a generic form, also below par.
One scene from the three months illustrates the pattern behind these findings. The agent had built a map visualising where conference attendees come from. Visually impressive, technically clean. Only on a closer look at the raw data did it become clear that only about a third of the attendee data was in the dataset at all: the affiliation fields were inconsistently populated, and the agent had not flagged this. What looked like an insight into where the community comes from would have been a visualisation that does not hold up. The lesson from moments like this is not "agents are useless." It is: without a human reading along with experience, any agent in productive responsibility is a liability.
A second observation follows from this, and it costs money in practice: data quality remains the load-bearing foundation. A polished visualisation built on a questionable data base now appears faster than ever, and it is more dangerous than an obviously bad dashboard, because it convinces.
Augmented Arrogance
The Stochastic Parrots debate (Bender, Gebru and others, 2021) framed the core point, and Yann LeCun has picked up the image: as impressive as large language models look in their agentic packaging, they are powerful pattern generators without understanding. From practice, I see a specific pathology emerging from this, one I called Augmented Arrogance in the two underlying talks, Beyond Agents and How We Automate Chaos.
The pattern: agents always produce an answer, and that answer always looks convincing. They do not ask back. They do not say "I am stuck, help me." They produce code that is formally clean and semantically wrong. They decide unprompted that a visualisation would be "better" with three extra elements. They insert steps no one asked for. Even explicit prompt instructions ("It is fine to ask for help if you get stuck") barely move the needle. The behaviour sits deep in the model and the system prompt.
This is the opposite of human uncertainty. An experienced junior engineer says: "I am not sure." An agent says: "Here is the solution." Even when it is wrong. In an enterprise context this turns into a concrete risk: a project lead sees highly polished output, trusts the system, and three weeks later a process breaks because a fundamental error has slipped through unnoticed.
That is the core risk of unsupervised agent use in companies. It is not the spectacular hallucination. It is the unobtrusive one.
Short Leash Principle
The direct response to this risk is a practice I call the Short Leash Principle. It has four components, all distilled from operations.
First: tight scoping of the use case
The agent does not solve "the problem"; it solves a concrete, clearly delimited task. Pull LinkedIn data: yes. "Develop a LinkedIn strategy": no. Produce rough video cuts: yes. Rework the editorial line of the social channels: no. This separation isn't modesty; it is risk management.
Second: frequent commits, and the right to reset
Agents loop, add code without deleting, drift away from the brief. Whoever commits frequently (or asks the agent to do so) can roll back to a clean state instead of disentangling an opaque layering of unrequested features. This is version control as governance.
Third: tool diet, not tool buffet
It is tempting to wire in every available MCP server, every sub-agent, every new framework. In practice it accelerates nothing: it disperses attention and the context window. Fewer tools, used deliberately, beat the full toolbox.
Fourth: explicit escalation, and the human as a reader
The agent must have a recognisable list of cases in which it is allowed to say: "I cannot do this, a human is needed here." And the human has to read the code, not just write the next prompt. The most honest finding from three months of practice: agents turn writers into readers. Whoever prompts more than they read is accumulating debt that comes due later, expensively.
Experienced engineers and data scientists do not become less important in this world; they become more valuable.
The strategic consequence: experienced engineers and data scientists do not become less important in this world; they become more valuable. Their centre of gravity shifts from pure building toward the role of reviewer and governance layer. Cutting these roles because "agents will soon do everything" hard-codes a structural weakness into the programme, one that only surfaces in audit or incident, and then expensively.
The 15-Percent Order of Magnitude
This experience meets an estimate I keep encountering in research, and that I see confirmed from work in comparable programmes: in an analytical or software-heavy programme, generative AI covers at most around 15 percent of the value created. The remaining 85 percent stay what they always were: analytics, machine learning, data quality, predictive modelling, security, governance.
This sounds like a technical statement. It is in fact an organisational one. It says: anyone investing primarily in agent tooling without continuing to build the classical disciplines is laying an unstable foundation. Agents accelerate a narrow slice. They do not replace the base. Building headcount planning on the opposite assumption, and cutting engineering roles, is a strategic miscalculation that only becomes visible once something breaks.
Innovation in this world does not happen inside individual agents. It happens at the seams: between domains, data sources, systems. That requires people who can read and shape those seams. Not people who prompt fast.
So What
The operational lesson from three months of work with various coding agents is unspectacular but load-bearing. Agents create value where tasks are documented, narrowly scoped and reviewable. They create risk where they are placed, without explicit governance, into processes involving judgement, data quality or multi-step dependencies, and they often fail there even when the task looks well-documented on the surface.
Anyone who skips this systematic thinking wires risks into their own stack that are hard to undo in audit or in an incident. The question is therefore not whether agents are used productively in an organisation. It is under which governance frame that happens. Both pieces, picking the right use cases and defining the review structure, are strategic decisions, not technical ones.
Selected Slides


What does the governance frame for agents look like in your programme?
Let's talkRelated links
Observations from running PyCon DE & PyData (1,500 attendees, volunteer-organised programme) and from the talks Beyond Agents (March 2025) and How We Automate Chaos (September 2025).